
Apache Kafka is a distributed streaming platform, which lets you publish and subscribe to streams of records. Apache Kafka is a community distributed event streaming platform capable of handling trillions of events a day. Initially conceived as a messaging queue, Kafka is based on an abstraction of a distributed commit log. Apache Kafka as a message buffer to protect a legacy database that can’t keep up with today’s workloads, or using the Connect API to keep said database in sync with an accompanying search indexing engine, to process data as it arrives with the Streams API to surface aggregations right back to your application.
Related article: How to install Apache Kafka on Ubuntu 18.04
- Apache Kafka and its API make building data-driven apps and managing complex back-end systems simple.
- Apache Kafka gives you peace of mind knowing your data is always fault-tolerant, re-playable and real-time.
- Helping you quickly build by providing a single event streaming platform to process, store, and connect your apps and systems with real-time data.
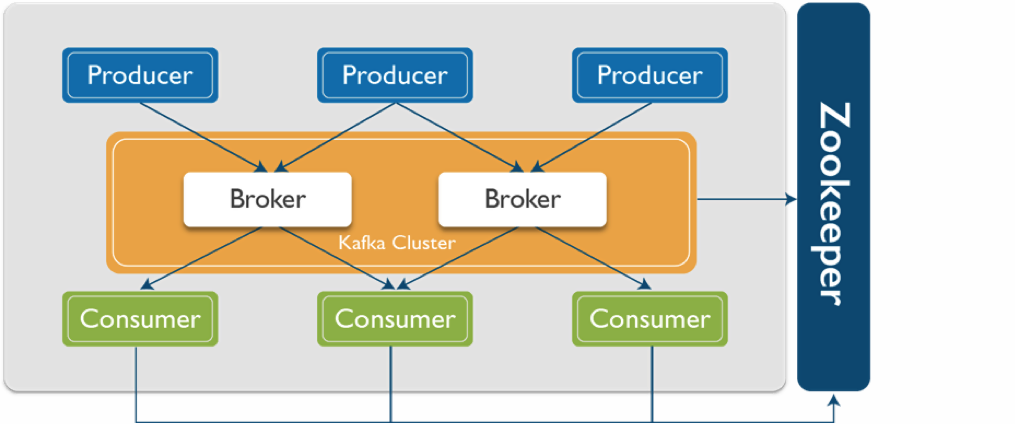
- In Kafka there are different components present in a Kafka system so let’s talk about these components.
Apache Kafka streaming platform has three key capabilities:
- Publish and subscribe to streams of records, similar to a message queue or enterprise messaging system.
- Store streams of records in a fault-tolerant durable way.
- Process streams of records as they occur.
Kafka is generally used for two broad classes of applications:
- Building real-time streaming data pipelines that reliably get data between systems or applications
- Building real-time streaming applications that transform or react to the streams of data
To understand how Apache Kafka does these things, let’s dive in and explore Kafka’s capabilities from the bottom up.
Initial Concepts:
- Kafka is run as a cluster on one or more servers that can span multiple data centres.
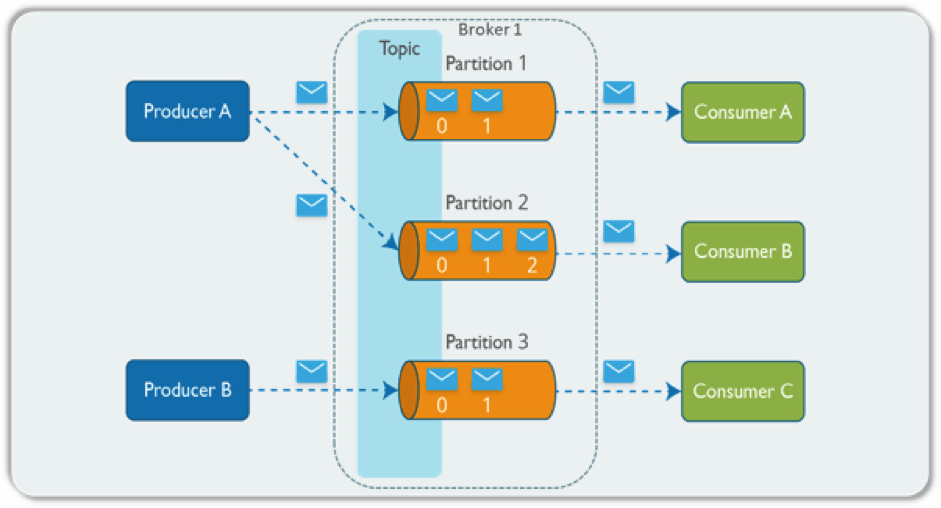
- The Kafka cluster stores streams of records in categories called topics.
- Each record consists of a key, a value, and a time stamp.
Kafka has four core API:
- The Producer API allows an application to publish a stream of records to one or more Kafka topics. The Producer API allows applications to send streams of data to topics in the Kafka cluster. To use the producer, you can use the following dependency:

- The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them. The Consumer API allows applications to read streams of data from topics in the Kafka cluster. To use the consumer, you can use the following dependency:
<Dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.3.0</version>
</dependency>
- The Stream API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams. The Streams API allows transforming streams of data from input topics to output topics.
To use Kafka Streams you can use the following dependency:
| <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-streams</artifactId> <version>2.3.0</version></dependency> |
- The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems.
- For example, a connector to a relational database might capture every change to a table.
- Many users of Connect won’t need to use this API directly, though; they can use pre-built connectors without needing to write any code.
In Kafka the communication between the clients and the servers is done with a simple, high-performance, language agnostic TCP Protocol. This protocol is version and maintains backwards compatibility with older version. We provide a Java client for Kafka, but clients are available in many languages.
How Can Apache Kafka Help You?
- Apache Kafka helps you with distributed commit log commonly found in distributed databases, through; Apache Kafka you can find much space.
- Additionally, Kafka act as a source of truth, being able to distribute data across multiple nodes for a highly available deployment within a single data center or across multiple availability zones.
- An event streaming platform would not be complete without the ability to manipulate that data as it arrives.
- The Streams API within Apache Kafka is a powerful, lightweight library that allows for on-the-fly processing, letting you aggregate, create windowing parameters, perform joins of data within a stream, and more.
- Moreover, it is built as a Java application on top of Kafka, keeping your work flow intact with no extra clusters to maintain.

Why Kafka is the best?
- Kafka has a unique design that makes it very useful for solving a wide range of architectural challenges.
- It is important to make sure you use the right approach for your use case and use it correctly to ensure high throughput, low latency, high availability, and no loss of data.
- Apache Kafka has great performance, and it is stable, provides reliable durability, has a flexible publish-subscribe/queue that scales well with N-number of consumer groups, has robust replication, provides Producers with tunable consistency guarantees, and it provides preserved ordering.